Modelo de Inteligencia Artificial para la Detección Temprana de Diabetes Mellitus Tipo 2
Mónica Oñate
Febrero 20247 minutosModelo de Inteligencia Artificial para la Detección Temprana de Diabetes Mellitus Tipo 2
La Diabetes Mellitus tipo 2 ha sido catalogada como la epidemia del siglo XXI tanto por su creciente magnitud como por su impacto en la enfermedad cardiovascular, primera causa de mortalidad en las sociedades desarrolladas. Las proyecciones de la Organización Mundial de la Salud (OMS) indican que, para el año 2045, se espera que alrededor de 693 millones de adultos a nivel mundial estarán afectados por esta patología, es por ello que el desarrollo de modelos predictivos basados en Inteligencia Artificial (IA) representa un avance significativo en la identificación temprana de esta enfermedad.
En Colombia se realizó un estudio de corte transversal por el Grupo de Investigación en Ingeniería Sostenible e Inteligente de la Universidad Cooperativa de Colombia, el Grupo de Investigaciones Microbiológicas y Biomédicas de Córdoba de la Universidad de Córdoba, el Laboratorio Clínico de Sincelejo, el Grupo de Investigación Interdisciplinario de la Universidad de Antioquia. Para dicho estudio de corte transversal se utilizaron datos de de acceso libre del Hospital de Diabetes de Sylhet (Bangladesh), el cual contiene los signos y síntomas de 520 individuos bajo supervisión médica. La información de esta base de datos fue obtenida mediante encuesta, que se aplicó a 320 pacientes con diagnóstico de diabetes y 200 individuos sin la enfermedad.
Los mapas cognitivos difusos son técnicas computacionales que buscan simular el razonamiento humano, similar a como lo realizan los expertos o cualquier persona con conocimientos sobre un tema en particular
El modelo alcanzó un 95% de exactitud, destacando por su capacidad para identificar la dinámica de los factores de riesgo de diabetes. Aunque las técnicas de IA como las máquinas de soporte vectorial y redes neuronales han sido exploradas para predecir la diabetes, el uso de FCM es menos común. Estudios recientes han comenzado a explorar los FCM para este fin, destacando su potencial en el análisis de relaciones entre síntomas y factores de riesgo.
En dicho estudio se utilizaron datos del Hospital de Diabetes de Sylhet, aplicando técnicas de sobremuestreo de minorías sintéticas y normalización para balancear y preparar los datos. Los FCM se entrenaron utilizando una estrategia mixta que combinó la experiencia médica con la Optimización por Enjambre de Partículas.
El modelo fue evaluado mediante exactitud, sensibilidad y especificidad, así como integraciones simuladas para analizar el comportamiento de las variables en el tiempo.
Este estudio demuestra los beneficios de la IA en la detección temprana de la diabetes. El modelo de FCM desarrollado no solo predice la enfermedad con alta exactitud, sino que también facilita el análisis de los factores de riesgo, contribuyendo así a reducir la morbilidad y mortalidad asociadas a la diabetes.
La información de esta base de datos fue obtenida mediante encuesta que se les hizo a 320 pacientes con diagnóstico de diabetes y a 200 individuos sin la enfermedad.
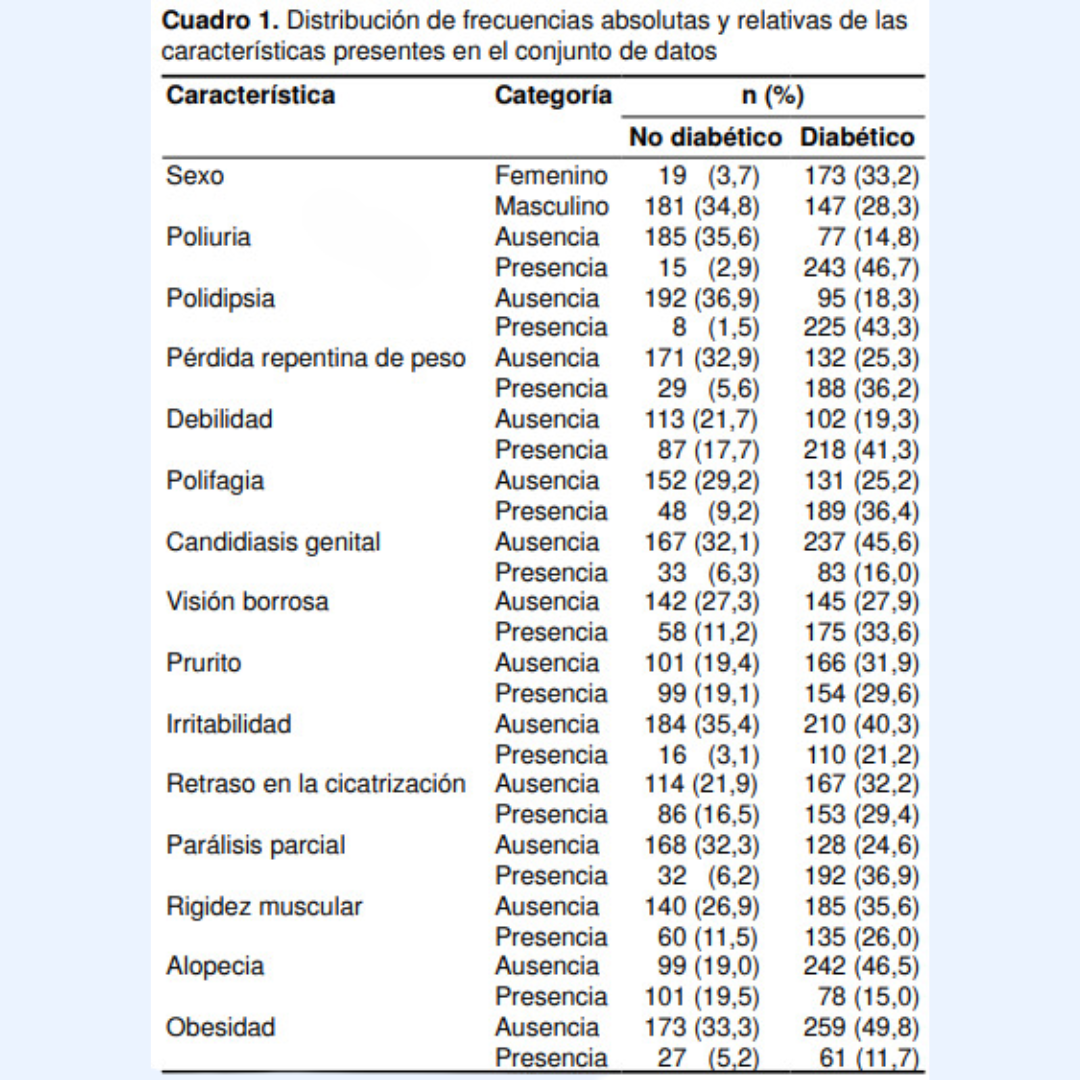 Se preguntaron 17 variables, como se aprecia en el cuadro 1, cuyas respuestas son binarias (sí/no), excepto la edad. Se hizo un análisis descriptivo del conjunto de datos, para conocer su distribución. En el análisis de las variables cualitativas (binarias), se utilizó la distribución por frecuencias absolutas y relativas, en relación con el diagnóstico de diabetes. Para el análisis de la edad, se emplearon medidas de tendencia central y de dispersión, tales como la media y la desviación estándar, respectivamente.
Se preguntaron 17 variables, como se aprecia en el cuadro 1, cuyas respuestas son binarias (sí/no), excepto la edad. Se hizo un análisis descriptivo del conjunto de datos, para conocer su distribución. En el análisis de las variables cualitativas (binarias), se utilizó la distribución por frecuencias absolutas y relativas, en relación con el diagnóstico de diabetes. Para el análisis de la edad, se emplearon medidas de tendencia central y de dispersión, tales como la media y la desviación estándar, respectivamente.
Preprocesamiento de los datos
Teniendo en cuenta que en el conjunto de datos la distribución de las clases se encontraba desequilibrada, con el 38,47 % de registros de individuos sin diabetes y el 61,53 % de registros de pacientes con diabetes, se utilizó la técnica de sobremuestreo de minorías sintéticas (Synthetic Minority Oversampling Technique, SMOTE). Mediante esta técnica, se muestrearon datos de la clase inferior; así, se generaron nuevas instancias a partir de los datos minoritarios existentes y se aumentó el número de datos para la etiqueta menor, es decir, se ajustaron a 320 registros de individuos sin diabetes frente a los 320 registros de pacientes con diabetes, obteniéndose un conjunto de datos con 640 registros equilibrados entre sus clases. También, se utilizó la técnica de normalización mín-máx para la edad, que fue la única variable numérica del conjunto de datos. Este procedimiento ayudó a mantener las variables en el mismo rango y, además, a optimizar el tiempo en el entrenamiento de los modelos.
Definición de un mapa cognitivo difuso
Los mapas cognitivos difusos son técnicas computacionales que buscan simular el razonamiento humano, en forma similar a como lo hacen los expertos o cualquier persona con conocimientos sobre un tema en particular. Para ello, se emplearon la representación gráfica de los elementos o conceptos que conforman un sistema y las relaciones entre estos. Desde su introducción por Kosko en 1986, los mapas cognitivos difusos han venido evolucionando y permitiendo la obtención de nuevo conocimiento en la última década. De esta forma, en la actualidad, un mapa cognitivo difuso es una poderosa herramienta para modelar sistemas con relaciones complejas.
Calibración y validación del mapa cognitivo difuso
Para la calibración y validación, se utilizó el 70 % de los datos y, para probar el modelo, se empleó el 30 % restante. Se utilizó la técnica de validación cruzada de cinco repeticiones, cuyo propósito fue obtener el mejor modelo y sus hiperparámetros. En la figura 2, se ilustra el proceso general de la validación cruzada de cinco repeticiones.
 Como se observa en el esquema, el conjunto de datos de calibración y validación (70 %) se subdividió en cinco subconjuntos, de los cuales se emplearon cuatro para la calibración y uno para la validación. Este mismo procedimiento se ejecutó sobre un subconjunto distinto del anterior, respetando la misma proporción (4:1) de datos. Luego de cinco iteraciones, se seleccionó el mejor modelo y sus hiperparámetros, con el cual se hicieron las pruebas de rendimiento, utilizando el 30 % de los datos del subconjunto de prueba. Para la calibración, se utilizaron múltiples configuraciones de parámetros, con el fin de hallar la mejor configuración en la construcción de un modelo de mapa cognitivo difuso. En el presente estudio, se adoptó una estrategia mixta: inicialmente, tres médicos internistas expertos en el manejo de la diabetes asignaron las influencias entre las variables del conjunto de datos, para luego optimizar el modelo mediante la aplicación de técnicas computacionales. En la práctica, esto permitió articular la intervención humana con uno de los algoritmos más utilizados para el diseño de dichos mapas: la optimización por enjambre de partículas (Particle Swarm Optimization, PSO), descrita así por Kennedy y Eberhart en 1995, por la similitud con el comportamiento de los enjambres de insectos en la naturaleza. Este es un algoritmo de búsqueda que se usó sobre el conjunto de datos para hallar el mapa cognitivo difuso que mejor describiera las relaciones entre los conceptos o variables. Esta estrategia permite la obtención de modelos de mapas cognitivos difusos óptimos para la descripción, predicción o evaluación del comportamiento de las características de un sistema en estudio.
Como se observa en el esquema, el conjunto de datos de calibración y validación (70 %) se subdividió en cinco subconjuntos, de los cuales se emplearon cuatro para la calibración y uno para la validación. Este mismo procedimiento se ejecutó sobre un subconjunto distinto del anterior, respetando la misma proporción (4:1) de datos. Luego de cinco iteraciones, se seleccionó el mejor modelo y sus hiperparámetros, con el cual se hicieron las pruebas de rendimiento, utilizando el 30 % de los datos del subconjunto de prueba. Para la calibración, se utilizaron múltiples configuraciones de parámetros, con el fin de hallar la mejor configuración en la construcción de un modelo de mapa cognitivo difuso. En el presente estudio, se adoptó una estrategia mixta: inicialmente, tres médicos internistas expertos en el manejo de la diabetes asignaron las influencias entre las variables del conjunto de datos, para luego optimizar el modelo mediante la aplicación de técnicas computacionales. En la práctica, esto permitió articular la intervención humana con uno de los algoritmos más utilizados para el diseño de dichos mapas: la optimización por enjambre de partículas (Particle Swarm Optimization, PSO), descrita así por Kennedy y Eberhart en 1995, por la similitud con el comportamiento de los enjambres de insectos en la naturaleza. Este es un algoritmo de búsqueda que se usó sobre el conjunto de datos para hallar el mapa cognitivo difuso que mejor describiera las relaciones entre los conceptos o variables. Esta estrategia permite la obtención de modelos de mapas cognitivos difusos óptimos para la descripción, predicción o evaluación del comportamiento de las características de un sistema en estudio.
Comportamiento de las variables usando iteraciones simuladas
Se evaluó el modelo desarrollado usando iteraciones simuladas para analizar el comportamiento de las variables involucradas.

En la figura 3, se muestra una representación esquemática de las simulaciones con mapas cognitivos difusos para diabetes. En el eje de las X de la gráfica, se muestran las iteraciones simuladas y, en el eje de las Y, se muestra el valor de las variables o conceptos. La simulación de esta figura corresponde a un paciente con poliuria, polidipsia y polifagia. Luego de varias iteraciones, el sistema logra un estado de equilibrio que indica que los conceptos no cambian de valor después de la iteración 72 (línea punteada anaranjada). En la figura 3, se puede observar cómo el modelo activa variables que no se encontraban presentes desde el inicio, como la candidiasis genital, la visión borrosa y el retraso en la cicatrización (todas estas variables representadas por la curva de color azul). Por otra parte, se ve que el concepto relacionado con el diagnóstico de la diabetes (curva roja) es activado desde la primera iteración, lo que indica que los síntomas alertan de manera temprana sobre la presencia de la enfermedad.
En los resultados de los parámetros de evaluación, el modelo obtuvo un gran rendimiento con una exactitud del 95 %, una sensibilidad del 96 % y una especificidad del 94 %, con los siguientes hiperparámetros: Initial population = 200; activation function = sigmoid; inference function = modified-Kosko.
Mirando hacia el futuro, este trabajo sienta las bases para investigaciones futuras y la implementación práctica de modelos predictivos en el ámbito de la salud. A medida que avanzamos, será crucial continuar mejorando y validando estos modelos con conjuntos de datos más amplios y diversos para garantizar su aplicabilidad y eficacia en diferentes poblaciones. La lucha contra la diabetes, se verá indudablemente fortalecida por el uso estratégico de la inteligencia artificial, marcando un camino prometedor hacia la detección temprana y la gestión efectiva de esta enfermedad crónica.




